Maximum Likelihood Estimation

Pdata x : 모집단
X = x개를 랜덤으로 추출. 샘플링
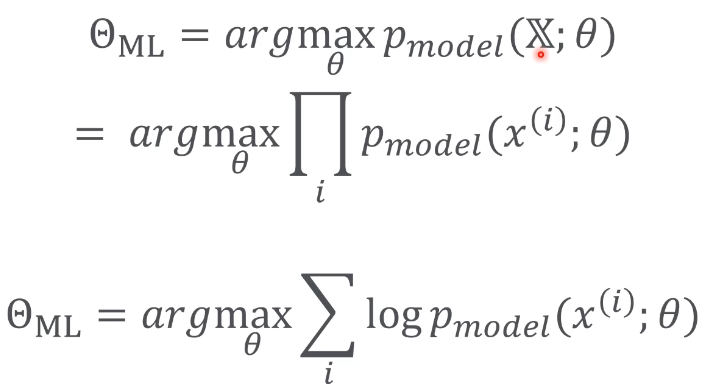
위 결과를 토대로
- Traning Data가 많아지면 모델이 정확해진다.
- Traning Data가 많아지면 일반화가 더 빨린된다.
- Consistency : i -> 무한대 인 경우, model과 실제 data간의 차이가 없어진다.
아래 두조건을 만족해야한다.
- data의 분포 종류가 모델의 분포종류와 같아야 한다.
- data의 분포의 세타가 정확히 하나의 값에 대응되어야한다. (여러개의 Normal Distribution에 대응하면 안됨)
Statistical efficiency
- 같은 Generalization Error 에 따른 필요 m의 수
- Generalization Error : Training Accuracy - Test Accuracy
단점
- Traning Data 에만 의존한다.
Classification & MLE


- Likelihood의 최대값을 찾는것은 Cross-entropy의 최소값을 찾는것과 같다.
따라서
-> Training Data 가 많아지면 모델이 정확해지고 일반화가 더 빨리된다
-> Training Data에만 맞게된다.
분류문제의 Cross-entropy loss function은 MLE의 이론적인 배경을 가지고 있다. 따라서 CLF은 MLE의 수학적인 특성을 가지고 있다.
Regression & MLE

Y값들이 Continuous 하다.
Classification에서는 유닛들이 여러개였고, 가장 원하는 레이블의 확률을 높이는게 목적이었다.
Regression은 결과값(Y')이 Y의 값과 가까워야 하는 것이다. Class 분류가 목적이라고 할 수 있다.


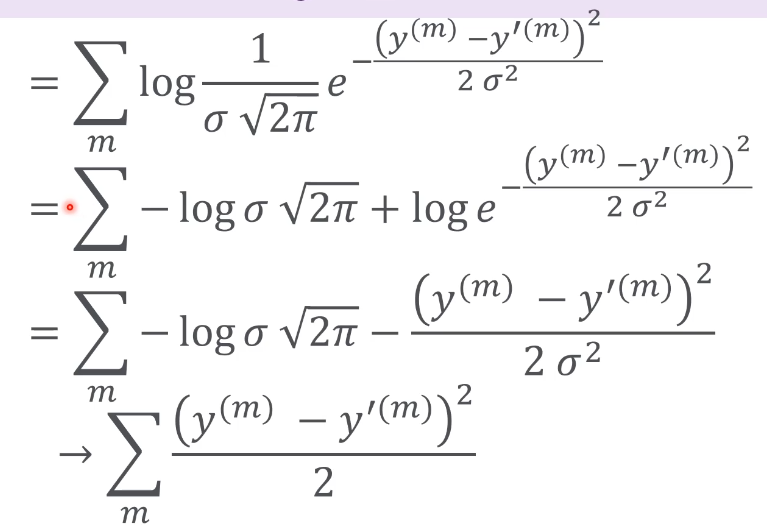
아래 그림의 Line의 좌표값들의 제곱의 값 합이 가장 적게 되는것을 찾는것이 MLE가 됨.

MLE는 통계학적 모델에서, 모델을 개발하고 모델을 정의할때 필요한 파라미터들을 계산하는것.
모집단을 샘플링을 하여 큰 집단을 예측하는데 MLE가 필요하다.
'머신러닝' 카테고리의 다른 글
| Maximum A Posteriori Estimation (0) | 2021.05.27 |
|---|---|
| Bayesian Estimation (0) | 2021.05.26 |
| Maximum likelihood Estimation 1 (0) | 2021.05.15 |
| 머신러닝이란? (0) | 2021.05.14 |
| Batch Normalization 2 & Well - Known Models & Recurrent Neural Network (0) | 2021.04.28 |




댓글