반응형
Optimizer란?
기본적으로 Weight updates를 하는 도구.
- loss를 줄이는 방향으로 updates.
Adaptive Gradient 방식

α : Learning rate
h : 기존의 h에 새로운 미분값을 더해줌. h가 커질수록 Learning rate는 작아짐.
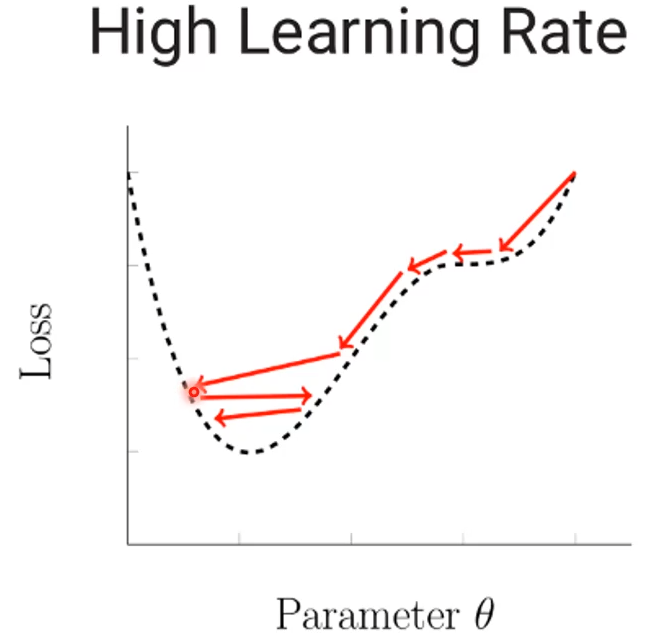
- 큰 러닝레이트는 필요한 값에 도달하지 못하고 반복하는 특징을 가지고 있음
- 러닝레이트가 갈수록 줄어든다면 값을 찾기 쉽다는 것에서 착안된 방법.
RMSProp 방식

- 이동 평균으로 구하는 방식
- 기존(ph)이 크면, 기존것이 더 많이 반영, 새로운 것이 크다면 새로운것이 더 많이 반영되게 되어진 방식.
Adam 방식
- AdaGrad + Momentum 방식이다.
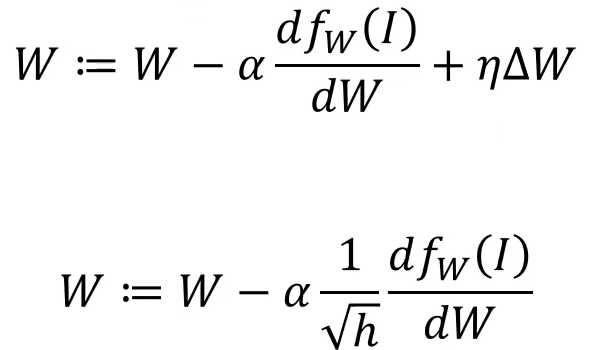
2D 차원에서의 각 방식별 비교
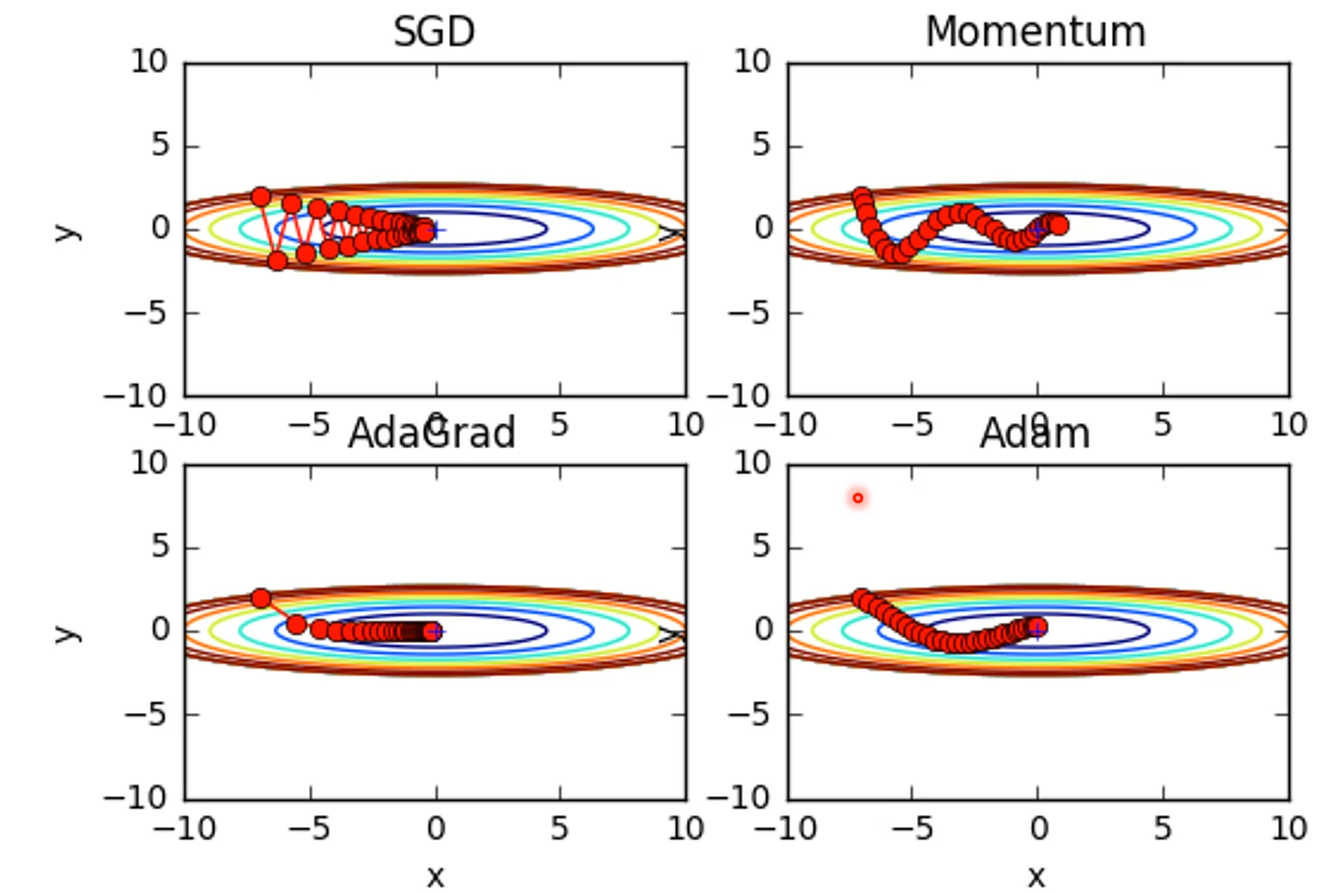
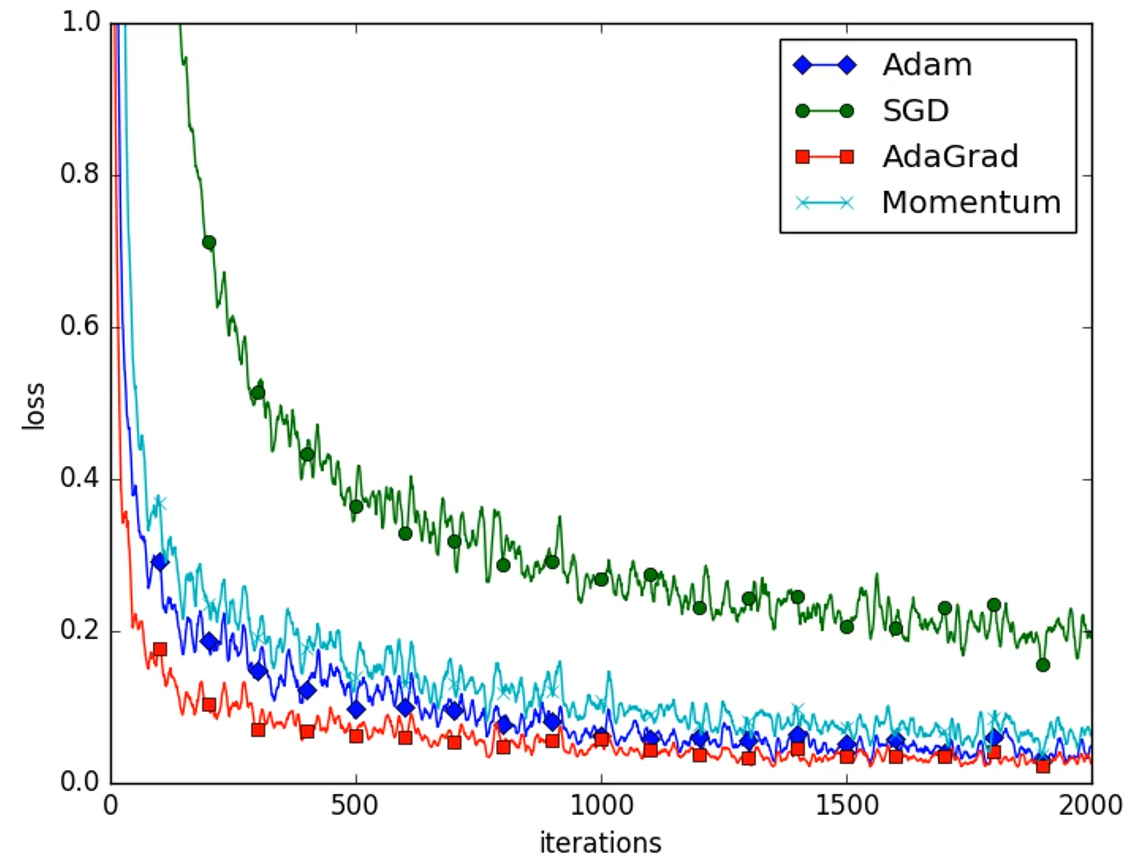
- 2D에서는 AdaGrad 방식이 가장 좋은 방법으로 보이지만, 더 많은 차원에서는 Adam 방식이 대체적으로 가장 좋은 성능을 보임.
- 주어진 환경, 모델에 따라 달라질 수 있음.
- 위 방법은 Torch에서 모두 간단하게 바꿀 수 있음.
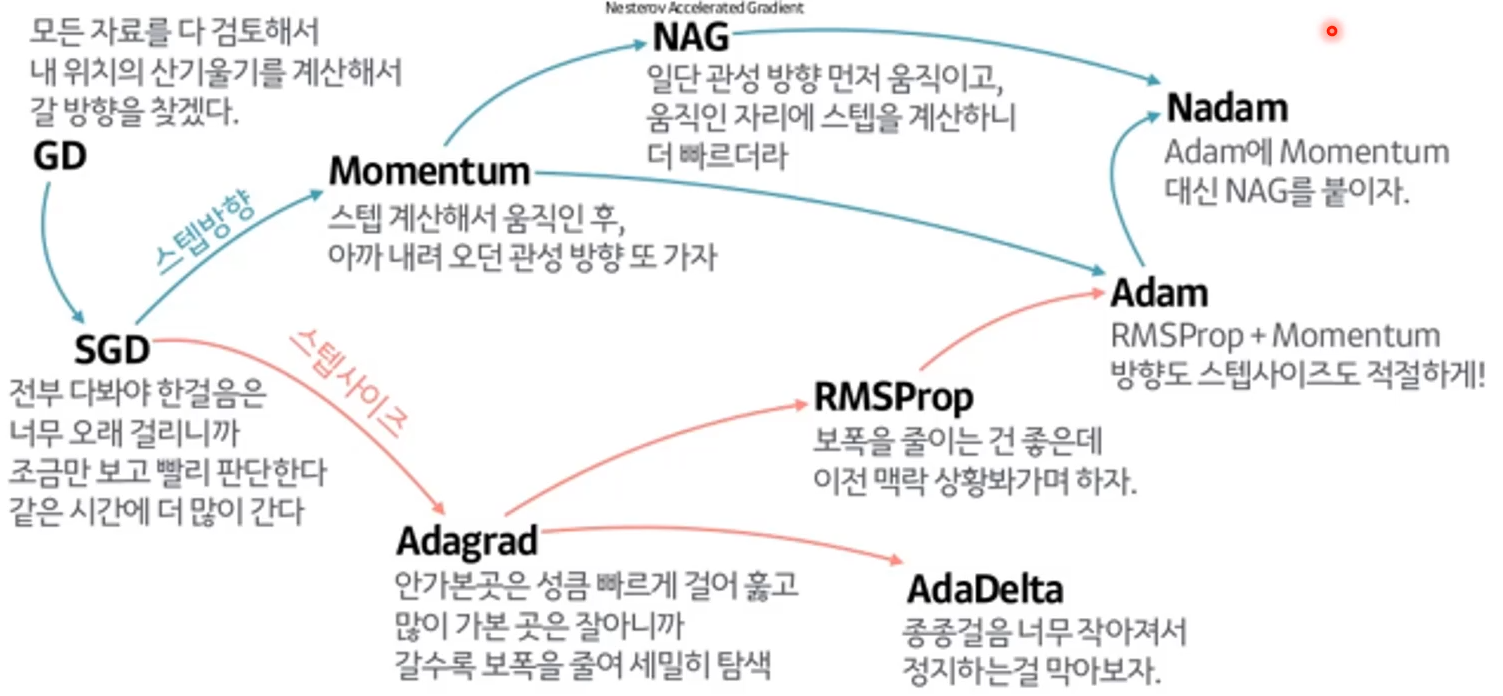
여러가지 방법 정리
반응형
'머신러닝' 카테고리의 다른 글
| Maximum likelihood Estimation 1 (0) | 2021.05.15 |
|---|---|
| 머신러닝이란? (0) | 2021.05.14 |
| Batch Normalization 2 & Well - Known Models & Recurrent Neural Network (0) | 2021.04.28 |
| Batch Normalization & Overfitting & HyperParameter (0) | 2021.04.23 |
| Initialization 2 (0) | 2021.04.22 |




댓글