Batch Normalization
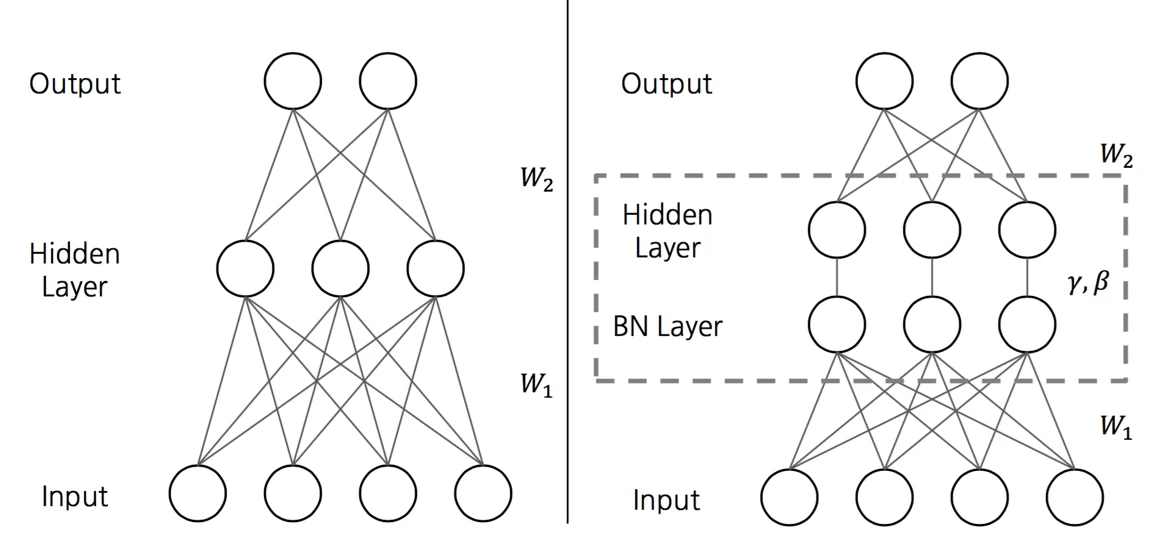
- 각각의 layer 마다 평균과 표준편차를 다시 구한다.
- BN을 적용한다면, W1 후의 Layer의 입력값이 균등하지 않아도, 균등하게 해주는 역할을 함.

- 초기값 W에 따른 여러 그래프
- 초기값을 잘못 설정한 W라도 BN를 통해 옳바른 값을 찾아가는것을 볼 수 있음.
Overfitting
분류문제

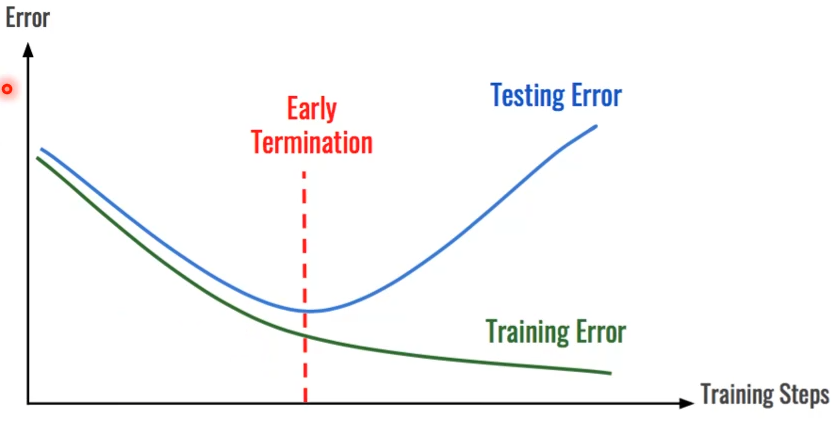
- Training Set에 과하게 학습되는것.
- 제한된 데이터에만 정확하게 맞는것을 의미함.
- Model의 Parameter 개수가 많을때와 Data가 적을때 이 현상이 일어난다.

- 추가적으로 Underfit 이란, 데이터의 특성을 완전히 잡아내지 못한것을 의미한다.
Overffting 방지법
Regularization

- Loss 함수에 새로운 항을 붙인다.
- weight 값의 크기를 제한하는 방법이다.
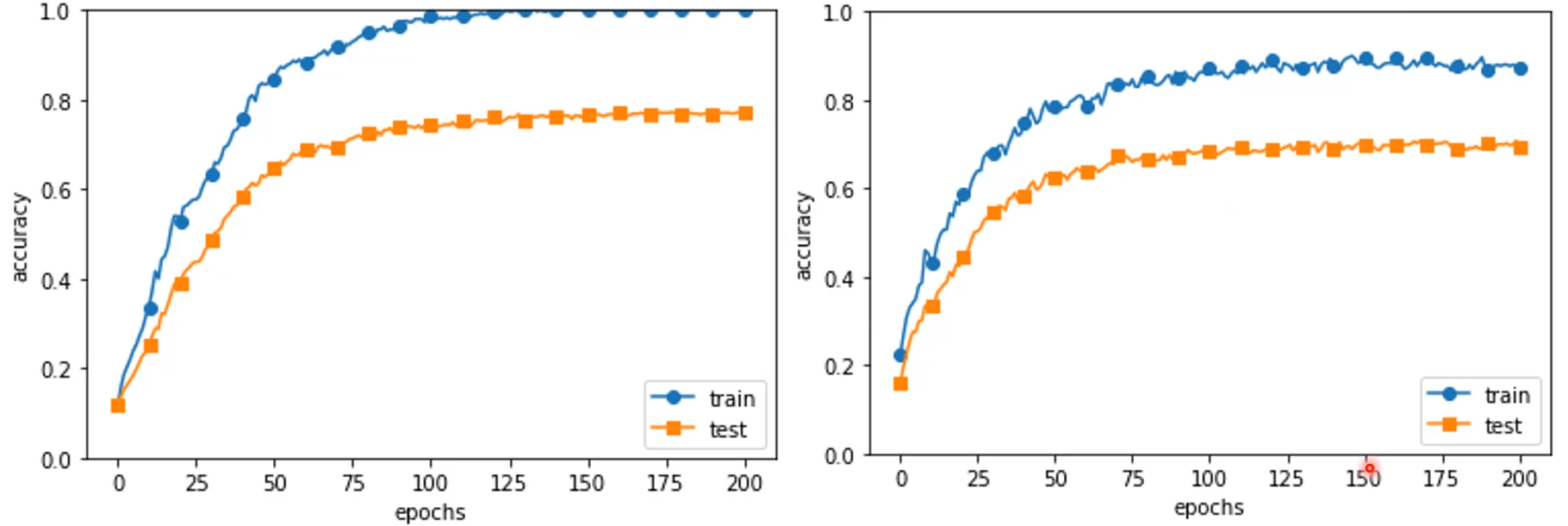
- Regularization을 통해 train과 test의 정확도 간극이 좁아졌다.
- 정확도가 언제나 높게 나오는 것은 아니다.
Dropout


Hyperparameter
- Weights 값과 Bias (Parameter)를 결정하는데 필요한 모든 변수값을 지칭하는말
- Learning rates, Momentum, Batchsize, units in layers 가 있음.
Hyper parameter 지정방법
0. Hyperparameter의 값의 범위를 지정
1. 설정된 범위에서 HP의 값을 무작위로 추출
2. 위 단계로 설정된 값으로 학습 후 정확도 판단 (단, 작은 데이터로. 예) Mnist의 6만개 데이터중 천개)
3. 1~2단계를 반복하여 정확도 결과를 보고 결정.
예시 )

>> 많은 컴퓨팅 파워를 요구하는 방법임.
>> 적은 컴퓨팅 파워일 때에는 조금씩 러닝 레이트를 수시로 고쳐가며 계산하게 됨.
'머신러닝' 카테고리의 다른 글
| Maximum likelihood Estimation 1 (0) | 2021.05.15 |
|---|---|
| 머신러닝이란? (0) | 2021.05.14 |
| Batch Normalization 2 & Well - Known Models & Recurrent Neural Network (0) | 2021.04.28 |
| Initialization 2 (0) | 2021.04.22 |
| Optimizer 2 (0) | 2021.04.21 |




댓글